Exploring the GitHub Advisory Database for fun and (no) profit
Principal Security Engineer Dakota Riley dives into the GitHub Advisory Database, cross referencing with other data sources and looking for interesting trends

If you have worked with any type of vulnerability or software composition analysis (SCA) tooling, you are likely aware of the various databases for package manager vulnerabilities. The GitHub Advisory database aggregates vulnerabilities from the language package managers, as well as community submitted entries related to open-source projects. It also powers Dependabot. I recently learned that the GitHub Advisory database is actually available via a public repository. I wanted to pull down the dataset and play with it via Pandas/Jupyter to see if we can discover anything interesting, and that is what this blog is about! In this blog, we will look at:
- How many GitHub Advisories exist for each language?
- How many advisories exist on the Known Exploited Vulnerabilities (KEV) list
- What are the most common types of vulnerabilities in the dataset?
- Looking at the advisories through the lens of the Exploit Prediction Scoring System (EPSS) scores
- GitHub Advisories without an assigned Common Vulnerabilities and Exposures (CVE) identifier
- Advisories within GitHub Actions workflows
Intro To The GitHub Advisory Dataset
Each GitHub advisory exists as a JSON file in the repository, conforming to a standard known as the Open Source Vulnerability format. At a high level, the format contains:
id: in this case will be the GHSA ID (GHSA-xxxx-xxxx-xxxx) unique to that advisory- Date fields for
modified,published, andwithdrawn aliases: containing an array of related CVE IDssummaryanddetailsfields, that contain information about the advisoryaffected: a nested structure containing information about the affected packages, and associated versionsdatabase_specific: The schema allows this field to be used for whatever additional information the database deems relevant. In the case of the GitHub Advisory database, it contains acwe_idskey with mapped CWE IDs, as well as a GitHub provided severity labelseverity, agithub_reviewedandgithub_reviewed_atfield, as well as anvd_published_atfield.
Getting the data
warning: a few of the steps are SLOW!
Start by cloning the repo:
git clone git@github.com:github/advisory-database.git
Now to jam the data into a Pandas dataframe for poking at it:
import pandas as pd
repo_path = '/advisory-database/advisories/github-reviewed/**/*.json'
json_files = glob.glob(repo_path, recursive=True)
data = []
for file in json_files:
with open(file, 'r') as f:
json_data = json.load(f)
data.append(json_data)
gh_adv = pd.DataFrame(data)
We can use the info() method to quickly sample the structure and size of our dataframe:
gh_adv.info()
RangeIndex: 16749 entries, 0 to 16748
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 schema_version 16749 non-null object
1 id 16749 non-null object
2 modified 16749 non-null object
3 published 16749 non-null object
4 aliases 16749 non-null object
5 summary 16748 non-null object
6 details 16749 non-null object
7 severity 16749 non-null object
8 affected 16749 non-null object
9 references 16749 non-null object
10 database_specific 16749 non-null object
11 withdrawn 261 non-null object
dtypes: object(12)
memory usage: 1.5+ MB
Don’t worry, the dataframe uses around 1.5 MB once loaded, and shouldn’t melt your computer. While we are at it, let’s also pull down some additional datasets to help us poke around:
from datetime import date
today = date.today()
d1 = today.strftime('%Y-%m-%d')
epss = pd.read_csv(f'https://epss.cyentia.com/epss_scores-{d1}.csv.gz', compression='gzip', header=1)
kev = pd.read_csv('https://www.cisa.gov/sites/default/files/csv/known_exploited_vulnerabilities.csv')
# getting the CWE categories for hardware, software, and research just to be safe
cwe1 = pd.read_csv('https://cwe.mitre.org/data/csv/699.csv.zip', compression='zip', index_col=False)
cwe2 = pd.read_csv('https://cwe.mitre.org/data/csv/1000.csv.zip', compression='zip', index_col=False)
cwe3 = pd.read_csv('https://cwe.mitre.org/data/csv/1194.csv.zip', compression='zip', index_col=False)
cwe = pd.concat([cwe1, cwe2, cwe3])
cwe = cwe[['Name', 'CWE-ID']]
cwe['cwe_id'] = cwe['CWE-ID'].apply(lambda x: f"CWE-{x}")
cwe_lookup = cwe[['cwe_id', 'Name']]
The above pulls in the EPSS scores for the current day, the KEV list, and all Common Weakness Enumeration (CWE) categories. We will use the KEV list and EPSS scores with the advisories to see what interesting things we can find. The CWE data will be used solely to help categorize the advisories for a high-level understanding of the vulnerability. They are labeled with the CWE IDs instead of the actual names of the weaknesses, for example, CWE-306 instead of “Missing Authentication for Critical Function.”
Some last data manipulation before we dive in!
# Move withdrawn advisories into a separate dataframe
# and remove them from the one we will use for analysis
gh_withdrawn = gh_adv[gh_adv['withdrawn'].isna() == False]
gh_adv = gh_adv[gh_adv['withdrawn'].isna()]
# Extract CVE IDs from nested array
gh_adv = gh_adv.explode('aliases', ignore_index=True)
# Set advisories with no CVE ID aside for analysis later
gh_adv_no_cve = gh_adv[gh_adv['aliases'].isnull()]
# add EPSS scores
gh_adv = pd.merge(gh_adv, epss, left_on='aliases', right_on='cve', how='left')
# add KEV status column
gh_adv['isKEV'] = gh_adv.aliases.isin(kev.cveID).astype(bool)
We can use the head() method to do a quick sanity check of our dataframe, limiting the columns for the purpose of the blog formatting:
gh_adv[['id', 'aliases', 'epss', 'isKEV']].head(3)
| # | id | aliases | epss | isKEV |
|---|---|---|---|---|
| 0 | GHSA-r9cr-hvjj-496v | CVE-2022-24730 | 0.00065 | False |
| 1 | GHSA-2j6v-xpf3-xvrv | CVE-2021-41193 | 0.00558 | False |
| 2 | GHSA-cr3q-pqgq-m8c2 | CVE-2018-25031 | 0.00265 | False |
Now we have a dataframe containing all non-withdrawn GitHub Advisories, along with their associated CVE ID, EPSS score, and KEV list status. Let’s analyze some data!
Ecosystems covered by the GitHub Advisory Database
As of the writing of the article, there are currently:
- 16749 total GitHub advisories.
- 261 have been withdrawn, leaving 16488.
- 1523 have no CVE associated with them (leaving 14965 with a CVE), which we will dive into later.
For counting things like common CWEs, ecosystems, packages, we will include the CVE-less advisories, but when we dive into things like EPSS scoring and presence on the KEV list, those will not be included, as both EPSS and the KEV list are tied to CVE IDs.
The GitHub Advisory database includes 12 ecosystems (package/dependency managers for languages):
Of those 16488, these are the vulnerability counts by each individual ecosystem:
| ecosystem | count |
|---|---|
| Maven (Java) | 4678 |
| npm (NodeJs) | 3248 |
| Packagist (PHP) | 2784 |
| PyPI (Python) | 2403 |
| Go | 1461 |
| RubyGems (Ruby) | 753 |
| crates.io (Rust) | 720 |
| NuGet (.NET) | 562 |
| SwiftURL (Swift) | 30 |
| Hex (Erlang) | 26 |
| GitHub Actions | 16 |
| Pub (Dart) | 6 |
It’s important to call out here that this shouldn’t be taken as a “ranking” of secure vs insecure languages, and i’d guess that there is some sort of correlation between the age of the language, its popularity, how much attention it gets from security researchers, and the number of vulnerabilities found in it.
Advisories present on the CISA KEV list
The CISA KEV list is an excellent way to get started with vulnerability prioritization relatively quickly and easily. I was really excited to see how many open-source vulnerabilities have evidence of exploitation in the wild!
Out of 14965 active GitHub Advisories with a CVE:
73 exist on the CISA KEV list (0.44%). While this seems small, it is actually consistent with the ratio of KEVs to all active CVEs: 239022 total CVEs to 1081 KEV listed vulnerabilities (0.45%). I had a feeling that this number would be small due to the nature of dependency vulnerabilities. This brings up an interesting conversation on how one would even really be able to identify if a vulnerable dependency actually played a part in the compromise of an application, aside from events like Log4j or vulnerabilities that affect an entire web framework like Spring, Struts, etc.
Makeup of the KEVs by ecosystem:
| Ecosystem | count |
|---|---|
| Maven (Java) | 39 |
| NuGet (.NET) | 14 |
| Packagist (PHP) | 8 |
| npm (NodeJs) | 6 |
| PyPI (Python) | 5 |
| Go | 4 |
| RubyGems (Ruby) | 2 |
| SwiftURL (Swift) | 1 |
| crates.io (Rust) | 1 |
Within those KEV listed advisories, we can use the CWE categories to get an idea of the types of vulnerabilities that are present on the list:
| CWE Name | count |
|---|---|
| Improper Control of Generation of Code (Code Injection) | 12 |
| Improper Input Validation | 12 |
| Deserialization of Untrusted Data | 8 |
| Improper Neutralization of Special Elements used in an Expression Language Statement (Expression Language Injection) | 6 |
| Out-of-bounds Write | 6 |
| Improper Neutralization of Special Elements used in an OS Command (OS Command Injection) | 5 |
| Improper Limitation of a Pathname to a Restricted Directory (Path Traversal) | 5 |
| Improper Restriction of Operations within the Bounds of a Memory Buffer | 4 |
| Unrestricted Upload of File with Dangerous Type | 3 |
| Inadequate Encryption Strength | 3 |
| Use After Free | 3 |
| Improper Neutralization of Special Elements in Output Used by a Downstream Component (Injection) | 3 |
| Improper Authentication | 3 |
| Improper Access Control | 3 |
| Improper Privilege Management | 2 |
| Initialization of a Resource with an Insecure Default | 2 |
| Protection Mechanism Failure | 2 |
| Uncontrolled Resource Consumption | 2 |
| Improper Neutralization of Special Elements used in a Command (Command Injection) | 1 |
| Missing Authentication for Critical Function | 1 |
| Relative Path Traversal | 1 |
| Exposure of Sensitive Information to an Unauthorized Actor | 1 |
| Access of Resource Using Incompatible Type (Type Confusion) | 1 |
The common CWEs amongst the KEV advisories aren’t surprising - I can see any type of code injection vulnerability being very enticing to attackers, things that aren’t terribly nuanced to exploit but often lead to compromise of the system. A malicious entity having the ability to execute arbitrary code is really tough to defend against.
As far as the specific packages and associated vulnerabilities, a few aren’t super surprising:
- Log4J Remote Code Injection and Fix (CVE-2021-44228, CVE-2021-45046)
- Multiple Apache Struts Remote Code Execution vulnerabilities (CVE-2013-2251, CVE-2017-9791, CVE-2018-11776, CVE-2017-5638, CVE-2017-9805, CVE-2012-0391)
- Multiple Spring Vulnerabilities (CVE-2022-22963, CVE-2018-1273, CVE-2022-22947)
Slightly more interesting:
- Jenkins has 2 vulnerabilities, adversaries understanding the value of attacking CI systems
- Minio, an object storage server with an S3 compliant API, has a privilege escalation vulnerability that has been observed being exploited
Something that stood out to me here was the number of advisories that were related to an open-source project that you deploy (Grafana, OctoberCMS, ElasticSearch, Jenkins, Airflow) vs projects that are actual dependencies/frameworks meant to be consumed in your code (Spring, Electron, Apache, golang.org/x/net, Log4J, etc).
Most common types of vulnerabilities across languages
Top CWEs across the entire GitHub Advisory dataset
warning: CWEs are counted once per package per advisory. An advisory can have one or more packages. So an advisory with two unique packages tagged with CWE-20 counts as CWE-20 appearing twice for the purposes of this count
Across the entire GitHub Advisory dataset, below is the most common CWEs:
| CWE Name | count | Rank in CWE top 25 2023 |
|---|---|---|
| Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 2599 | 2 |
| Improper Limitation of a Pathname to a Restricted Directory (Path Traversal) | 840 | 8 |
| Improper Input Validation | 807 | 6 |
| Exposure of Sensitive Information to an Unauthorized Actor | 746 | N/A |
| Uncontrolled Resource Consumption | 669 | N/A |
| Cross-Site Request Forgery (CSRF) | 592 | 9 |
| Deserialization of Untrusted Data | 430 | 15 |
| Improper Control of Generation of Code (Code Injection) | 429 | 23 |
| Embedded Malicious Code | 378 | N/A |
| Missing Authorization | 372 | 11 |
| Out-of-bounds Write | 357 | 1 |
| Improper Neutralization of Special Elements used in an SQL Command (SQL Injection) | 328 | 3 |
| Improper Authentication | 314 | 13 |
| Improperly Controlled Modification of Object Prototype Attributes (Prototype Pollution) | 306 | N/A |
| Incorrect Authorization | 290 | 24 |
| Improper Neutralization of Special Elements used in an OS Command (OS Command Injection) | 283 | 5 |
| Improper Neutralization of Special Elements in Output Used by a Downstream Component (Injection) | 275 | N/A |
| Improper Restriction of XML External Entity Reference | 274 | N/A |
| Improper Neutralization of Special Elements used in a Command (Command Injection) | 271 | 16 |
| Improper Access Control | 249 | N/A |
I included the 2023 CWE Top 25 rank, which incorporated all CVE Records in 2021 and 2022 to get an idea of how the top CWEs in the GitHub Advisory database stack up against the entire CVE set.
Top 3 CWEs for each GitHub Advisory ecosystem
After looking at this from the view of the entire dataset, I wondered if it differed by language/ecosystem. Below is a breakdown of the top 3 CWEs by ecosystem:
| ecosystem | Name | counts |
|---|---|---|
| GitHub Actions | Improper Neutralization of Special Elements used in a Command (Command Injection) | 4 |
| GitHub Actions | Improper Input Validation | 2 |
| GitHub Actions | Insertion of Sensitive Information into Log File | 2 |
| Go | Uncontrolled Resource Consumption | 138 |
| Go | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 116 |
| Go | Improper Input Validation | 116 |
| Hex | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 4 |
| Hex | Improper Input Validation | 2 |
| Hex | Uncontrolled Resource Consumption | 2 |
| Maven | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 710 |
| Maven | Deserialization of Untrusted Data | 338 |
| Maven | Cross-Site Request Forgery (CSRF) | 332 |
| NuGet | Out-of-bounds Write | 191 |
| NuGet | Buffer Copy without Checking Size of Input (Classic Buffer Overflow) | 116 |
| NuGet | Improper Input Validation | 92 |
| Packagist | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 1081 |
| Packagist | Exposure of Sensitive Information to an Unauthorized Actor | 174 |
| Packagist | Improper Neutralization of Special Elements used in an SQL Command (SQL Injection) | 152 |
| Pub | Improper Neutralization of CRLF Sequences (CRLF Injection) | 1 |
| Pub | Improper Neutralization of Special Elements in Output Used by a Downstream Component (Injection) | 1 |
| Pub | Insufficient Entropy | 1 |
| PyPI | Improper Input Validation | 300 |
| PyPI | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 247 |
| PyPI | Out-of-bounds Read | 215 |
| RubyGems | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 146 |
| RubyGems | Improper Input Validation | 53 |
| RubyGems | Exposure of Sensitive Information to an Unauthorized Actor | 49 |
| SwiftURL | Improper Limitation of a Pathname to a Restricted Directory (Path Traversal) | 3 |
| SwiftURL | Uncontrolled Resource Consumption | 3 |
| SwiftURL | Integer Overflow or Wraparound | 3 |
| crates.io | Concurrent Execution using Shared Resource with Improper Synchronization (Race Condition) | 68 |
| crates.io | Out-of-bounds Write | 51 |
| crates.io | Use After Free | 49 |
| npm | Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 478 |
| npm | Embedded Malicious Code | 380 |
| npm | Improperly Controlled Modification of Object Prototype Attributes (Prototype Pollution) | 306 |
Cross-site scripting is still very common, appearing in 7 of the ecosystems top 3 CWEs.
Embedded malicious code being one of the top 3 in the NPM ecosystem really surprised me and it was also the only ecosystem that had that particular CWE. It shocked me enough to triple-check that my query was right by searching via the web-ui. Something that stood out - the names of the submissions were very similar, and appear to have been submitted in batches. My gut feeling is that these are likely campaigns from researchers or maintainers of NPM bulk taking down malicious packages and submitting notices. I’d be very shocked if these types of things weren’t going on in the PyPI and RubyGems ecosystems (hint: they are, maybe I dig deeper into that in the future).
Some of the ecosystems, like Pub, Swift, and Hex, have so few advisories that the CWE counts for them aren’t particularly interesting.
Two of the top Rust CWEs are memory-related, which is interesting because the Rust language is actually designed to prevent these types of issues via its compiler and memory model (see the Ownership section of the Rust book for more details on this). My suspicion here is these were instances where the unsafe functionality of Rust was required and used insecurely. I took a look at GHSA-8f24-6m29-wm2r and saw the usage of the unsafe keyword. It’s very important to call out that the unsafe keyword isn’t by itself a bad thing. From the rust docs:
In addition, unsafe does not mean the code inside the block is necessarily dangerous or that it will definitely have memory safety problems: the intent is that as the programmer, you’ll ensure the code inside an unsafe block will access memory in a valid way.
Advisories With High EPSS Scores
There are 263 GitHub Advisories that have an EPSS score of 0.6 or greater.
43 of those are on the KEV list, leaving 210 GitHub Advisories that have that EPSS score without being on the KEV list.
EPSS scores of all GitHub Advisories
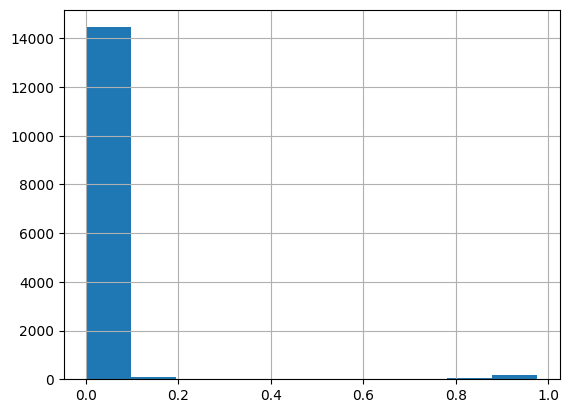
- The average EPSS score across all advisories:
0.02 - The highest EPSS score is
0.97565, belonging to CVE-2021-44228 aka Log4j - The median value of all advisories:
0.00108 - 87% of GitHub advisories have an EPSS score less than or equal to
0.1
The spread of EPSS scores across the GitHub advisory database is heavily weighted towards the lower end of the the spectrum, hence the funny looking histogram. Interestingly enough, this isn’t far off from the average EPSS score of ALL CVEs, which is 0.03
The EPSS scores of KEV listed GitHub advisories:
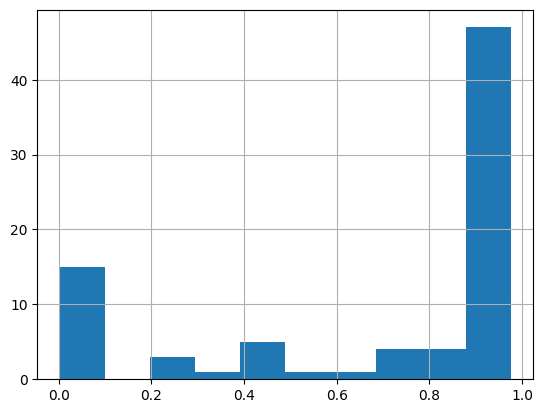
- The average EPSS score across the KEV listed advisories:
0.7 - The median EPSS score across the KEV listed advisories ` 0.97117 `
- There are 15 advisories that are present on the KEV list but have an EPSS score of
0.1or below
GitHub Advisories Without CVEs
In the dataset, there are 1523 GitHub Advisories with no CVE. While not my preferred approach, I used the GitHub provided severity as a starting point:
| severity | count |
|---|---|
| CRITICAL | 500 |
| HIGH | 430 |
| MODERATE | 409 |
| LOW | 184 |
I was hoping for a lower number of Critical/High severity ones I could work through. So I try sorting by CWE:
| Name | count |
|---|---|
| Embedded Malicious Code | 332 |
| Improper Neutralization of Input During Web Page Generation (Cross-site Scripting) | 122 |
| Uncontrolled Resource Consumption | 68 |
| Improper Limitation of a Pathname to a Restricted Directory (‘Path Traversal’) | 38 |
| Improperly Controlled Modification of Object Prototype Attributes (Prototype Pollution) | 32 |
| Exposure of Sensitive Information to an Unauthorized Actor | 32 |
| Improper Neutralization of Special Elements used in a Command (Command Injection) | 31 |
| Improper Input Validation | 20 |
| Improper Neutralization of Special Elements used in an SQL Command (SQL Injection) | 14 |
| Concurrent Execution using Shared Resource with Improper Synchronization (Race Condition) | 13 |
Seeing the “Embedded Malicious Code” at the top of the list makes sense, I imagine its viewed more in the category of a “security incident”, and not necessarily a vulnerability, thus not warranting a CVE.
I wasn’t really able to understand why categories outside of that don’t have a CVE. My best guess is that whomever submitted them didn’t go through the process of obtaining a CVE?
GitHub Actions Advisories
I learned throughout this process that there are advisories for GitHub Actions. GitHub Actions are templated workflows that you can use in GitHub CI pipelines; an example would be configure-aws-credentials. While I have seen research talking about the topic of compromising vulnerable GitHub Actions workflows, seeing it in the GitHub Advisory dataset was very surprising.
- There are 16 advisories referring to GitHub Actions workflows
- 2 of those don’t have a CVE associated with them
- The average EPSS score of these is
0.002. with a max0.00676, which isn’t super surprising given how niche and relatively unknown these are
| Name | count |
|---|---|
| Improper Neutralization of Special Elements used in a Command (Command Injection) | 4 |
| Insertion of Sensitive Information into Log File | 2 |
| Improper Neutralization of Special Elements in Output Used by a Downstream Component (Injection) | 2 |
| Improper Input Validation | 2 |
| Improper Control of Generation of Code (Code Injection) | 1 |
| Improper Neutralization of Special Elements used in an OS Command (OS Command Injection) | 1 |
| Improper Neutralization of Formula Elements in a CSV File | 1 |
| Incorrect Permission Assignment for Critical Resource | 1 |
| Exposure of Sensitive Information to an Unauthorized Actor | 1 |
| Cleartext Storage of Sensitive Information | 1 |
| Buffer Copy without Checking Size of Input (Classic Buffer Overflow) | 1 |
Given that there are only 16, I was able to manually read through each one and summarize at a high level:
- A few accidentally expose secrets into build logs, mostly due to not implementing GitHubs Secrets or environment variable functionality correctly
- Others actually pass user input from GitHub features (For example branch names, PR Names, or GitHub Issue titles) into code evaluation unsafely resulting in command injection
- Two GitHub actions (both from the same author) that allow one to inject commands via filenames
- One GitHub action had a binary baked into it that was vulnerable to memory overflow
The EPSS scores and numbers don’t really do these justice, as I could see these being really scary if present on a public repository. While I don’t believe you should overturn your current security priorities for this, it could be an interesting space to watch. To get an idea of the impact, I pulled some repo metadata from each of them (Stars, Forks, and Open Issues), which might give us an idea of how popular each was.
| Name | Stars | Forks | Open Issues |
|---|---|---|---|
| actions/runner | 4378 | 811 | 443 |
| tj-actions/changed-files | 1409 | 160 | 1 |
| gradle/gradle-build-action | 634 | 86 | 6 |
| hashicorp/vault-action | 400 | 134 | 21 |
| rlespinasse/github-slug-action | 235 | 34 | 1 |
| check-spelling/check-spelling | 227 | 31 | 15 |
| tj-actions/branch-names | 178 | 25 | 0 |
| tj-actions/verify-changed-files | 130 | 21 | 0 |
| Azure/setup-kubectl | 107 | 45 | 5 |
| afichet/openexr-viewer | 82 | 5 | 15 |
| atlassian/gajira-create | 56 | 37 | 15 |
| advanced-security/ghas-to-csv | 29 | 14 | 2 |
| kartverket/github-workflows | 5 | 2 | 4 |
| embano1/wip | 0 | 1 | 0 |
Not shown is GHSA-hw6r-g8gj-2987, an advisory against an action that was actually embedded within the pytorch repo itself, as opposed to being a standalone repo for a GitHub action meant to be consumed by the community (like ghas-to-csv for example).
Another interesting fact is the top one, actions/runner, is not actually a GitHub Action workflow but rather “the application that runs a job from a GitHub Actions workflow.” It makes sense to classify it as a GitHub Action related vulnerability.
Conclusion
The world of vulnerability data is incredibly nuanced and complex. Trying to find the 2-3 vulnerabilities that really matter when you are slammed with thousands is a tough challenge. I still believe infrastructure and workload context are key to this, as well as preventative approaches, but understanding the vulnerability landscape, and the various tools like the KEV list and EPSS scoring doesn’t hurt. I admittedly started this as a fun project to up my Pandas skills and left having learned more about the landscape of open-source vulnerabilities. Hopefully, you learned something too!
If you have any questions, or would like to discuss this topic in more detail, feel free to contact us and we would be happy to schedule some time to chat about how Aquia can help you and your organization.